System Architecture
Distribution
The distributed architecture of jadice flow offers high availability and high performance due to its immanent scalability.
Here you can see a typical jadice flow deployment.
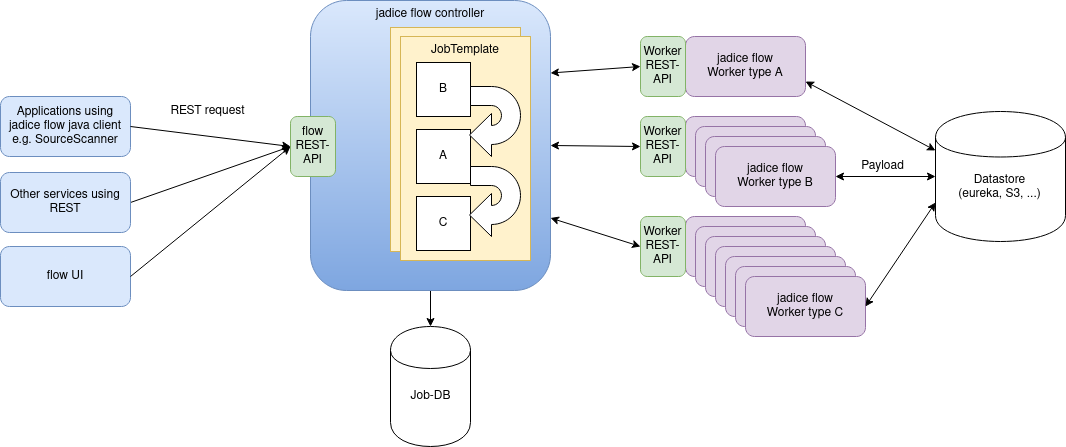
Fig. 1 jadice flow stack interactions and scaling
Scaling
Since most of the processing load is on the workers, those are scaled up (visualized by their purple containers in Fig. 1). It is not intended to scale the flow controller or run controller and workers in the same pod. The products all respect these demands, so you don't have to worry about Pod composition.
Components
As you can see in Fig. 1, jadice flow stack consists of the following components:
![]() controller
controller
jadice flow controller serves as transparent service that hands off the execution of jobs to workers. It provides the current job status to the client whilst abstracting away the scalability-related aspects of workers.
Therefore, jadice flow controller is the only communication endpoint of a client to handle jobs.
![]() controller database
controller database
Required to persist the job metadata. The default implementation in the deployment files is MariaDB, but you can use any other relational database management system of your choice. The database can be part of the stack or external.
![]() worker
worker
Each worker performs a specific functionality and is packaged as a Docker container.
![]() data store
data store
Data store for input & output documents and data. The default implementation is a eureka service, but other types like S3 and WebDAV are also supported.
![]() Source scanner
Source scanner
Optional component which polls a data source regularly to automatically create jobs in jadice flow to be processed.
For different ways of running a jadice flow stack see Kubernetes or Docker installation.