Job Processing
Components
Worker
In the jadice flow universe, the smallest processing unit is a step (which usually runs inside a worker container).
Workers are constructed as microservices - each of them running in its own Docker container.
Client
Clients request the execution of jobs via REST, providing job instructions and metadata in JSON. They can either send requests directly via the REST interface or use a Java Client library (flow-client) which is also provided.
Controller
Client place their orders (jobRequests) with the controller, an essential proxy service,
- that instructs other services (workers) to process documents,
- takes care of load balancing incoming requests to the different workers
- and creates a journal of performed jobs.
Processing
Fig. 1 shows how client, controller and workers play together in job processing. You can also access the controller with plain REST calls, as shown in Fig. 2.
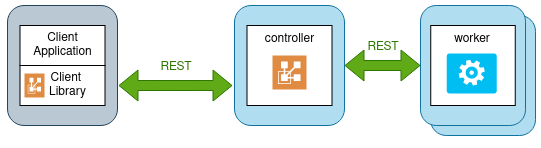
Fig. 1 High level architecture, using Java Client Libraray
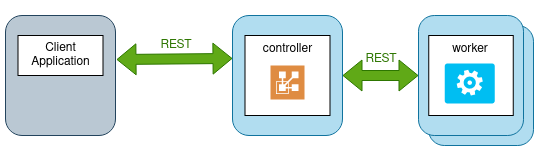
Fig. 2 High level architecture, using REST only
Metadata and payload
The JSON content of a client request contains metadata required to perform the job - but not the payload data. The payload - usually document content - is referenced by a URI (e.g. an S3 address) that points to an external data store. This is shown in Fig. 3.
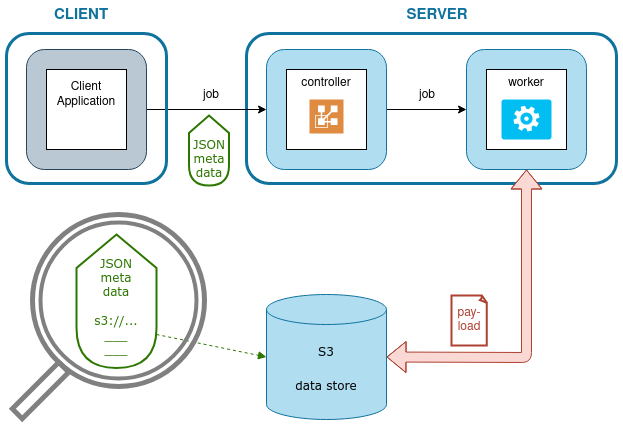
Fig. 3 Job processing in a simple jadice flow deployment
What are the steps involved?
- The controller receives job metadata, that references to the payload stored in S3.
- The controller hands off the job execution to a worker.
- The worker fetches the referenced payload data from the S3 data store, performs its task and stores its result back to the S3 data store. It sends back a JSON response to the controller that references this result.
- The controller receives worker results and updates the job accordingly (e.g. a new converted image added)
- The job status can be queried on the controller
- The result part S3 URLs can be used to obtain the result from the S3 data store.
Starting a job
To start a job, a JobRequest has to be created. The request must contain the name of the JobTemplate. Additionally, 1-n Items should be provided which shall be processed.
Usually, a request contains items with parts (the source / input data) which are processed to a target format. The binary part data must be provided in the configured storage before sending the request. The valid URLs (e.g. S3) to the part data must be present in the request.
The controller provides a rest API which can be used in multiple ways - please check the corresponding links for more information:
- use the jadice flow java client
- direct usage of the rest api
- use the optional
SourceScannercomponent, which acts like a flow client and is able to poll other data sources (e.g. folders for XML files) to create jobs in the controller (via rest). It also performs the upload of the input data into the storage.