Systemarchitektur
Der jadice server kann geclustert betrieben werden. Somit lässt sich eine hohe Verfügbarkeit bei gleichzeitig hoher Leistungsfähigkeit realisieren. Pro Serverinstanz wird jadice server in einer JVM ausgeführt und verwaltet jeweils einen Pool von LibreOffice-Prozessen bzw. verschiedene COM-Server. Über ein Messagingsystem (MOM), das als Transportschicht fungiert, fordern Clients die Ausführung von Jobs an. Der Zugriff durch die Clients erfolgt über eine Client-Bibliothek
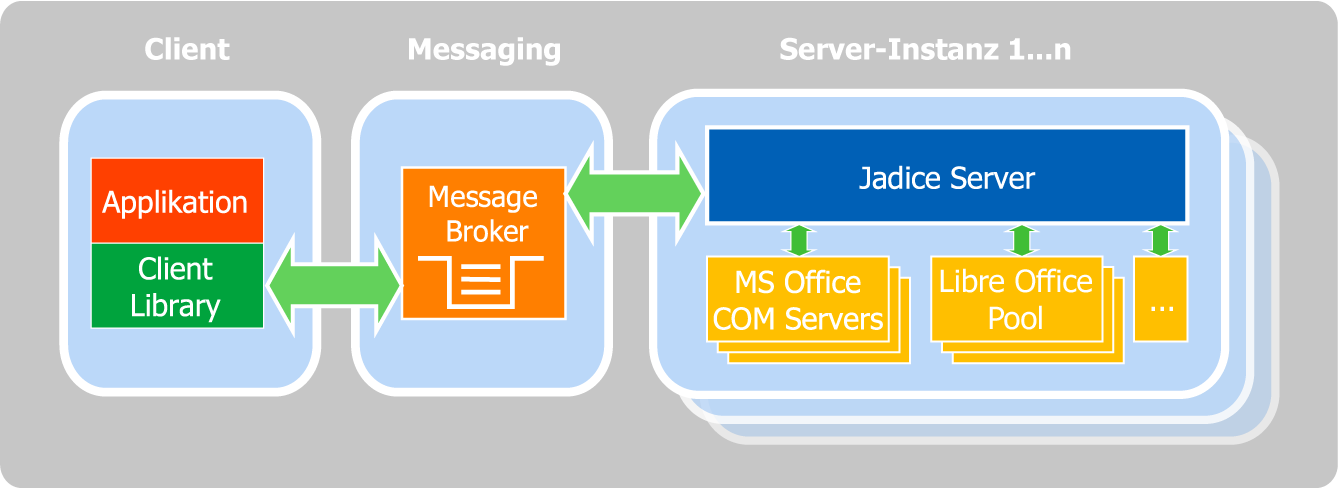 Abbildung 4.1. Messagingsystem als Transportschicht zwischen Clients und dem jadice server
Abbildung 4.1. Messagingsystem als Transportschicht zwischen Clients und dem jadice server
Da das Messagingsystem über die standardisierte JMS-Schnittstelle (Java Message Service) angebunden wird, können bereits im Unternehmen verwendete Messagebroker in die Systemarchitektur eingebunden werden.
Durch diese Architektur lässt sich mit einem geringen Aufwand ein automatisches Load-Balancing bei gleichzeitig hoher Verfügbarkeit realisieren.
Arbeitsweise
 Abbildung 4.2. Beschreibung eines Jobs durch einzelne Knoten
Abbildung 4.2. Beschreibung eines Jobs durch einzelne Knoten
Der jadice server ist so konzipiert, dass die Verarbeitung von
Dokumenten und Dokumentdaten in Aufträge (_JOBs) und diese wiederum in
einzelne Verarbeitungsschritte (Knoten, Nodes) zerlegt wird, die
dadurch einen Workflow beschreiben. Clients steuern die Ausführung der
Aufträge und verteilen sie über das Messagingsystem an den jadice
server.
Knoten sind die einzelnen, individuell definierten Aufgabenschritte, aus denen ein Job besteht. Sie sind untereinander durch Bündel von Datenströmen verbunden, die Nutzdaten sowie Metadaten transportieren. Die Verarbeitungsschritte sind daher in Bezug auf Inhalt und Reihenfolge abhängig vom auszuführenden Job.
Die Knoten unterscheiden sich voneinander in ihrer Aufgabenstellung. So können z. B. in einem Knoten Dokumente mit LibreOffice, MS Office oder den Funktionalitäten der jadice document platform konvertiert werden, während in einem anderen Knoten Dokumente geteilt oder zusammengeführt werden. Weitere Knoten können Metadaten aufbereiten und Daten formatieren. Die Druckaufbereitung von Dokumenten, die Rasterisierung und Bereitstellung von Daten als Tile-Server und die Klassifizierung von Datenströmen sind weitere Beispiele für Knoten. Selbst das einfache Aus- oder Einpacken von Daten aus oder in Archive geschieht in solch einem Verarbeitungsschritt.
Hierbei ist nicht fest vorgeschrieben, dass jeder Knoten genau einen
Vorgänger bzw. einen Nachfolger hat. So gibt es beispielsweise bereits
den vordefinierten Knoten _MULTIPLEXERNODE, der einen Datenstrom
vervielfältigt und an mehrere nachfolgende Knoten weiter gibt sowie den
Knoten DemultiplexerNode, der mehrere Vorgängerknoten hat und alle
einkommenden Datenströme an nur einen Nachfolger weiterreicht. Einzige
Bedingung bei der Konfiguration des Workflows ist nur, dass beim
Zusammenstellen der Nodes keine Zyklen entstehen dürfen.