Workflows
Configuration objects
Ready-to-deploy configuration
A default workflow configuration is with a jobtemplate.yaml already part of the products. In advanced use cases it might be necessary to modify job templates or change the configuration.
Basics
To define workflows, jadice flow uses so called JobTemplates. A JobTemplate can consist of 1-n StepTemplates which define which steps to run and which configuration to use.

A StepTemplate is a single piece of work inside a job, e.g. "Decompress ZIP", or "Convert JPEG to PDF"
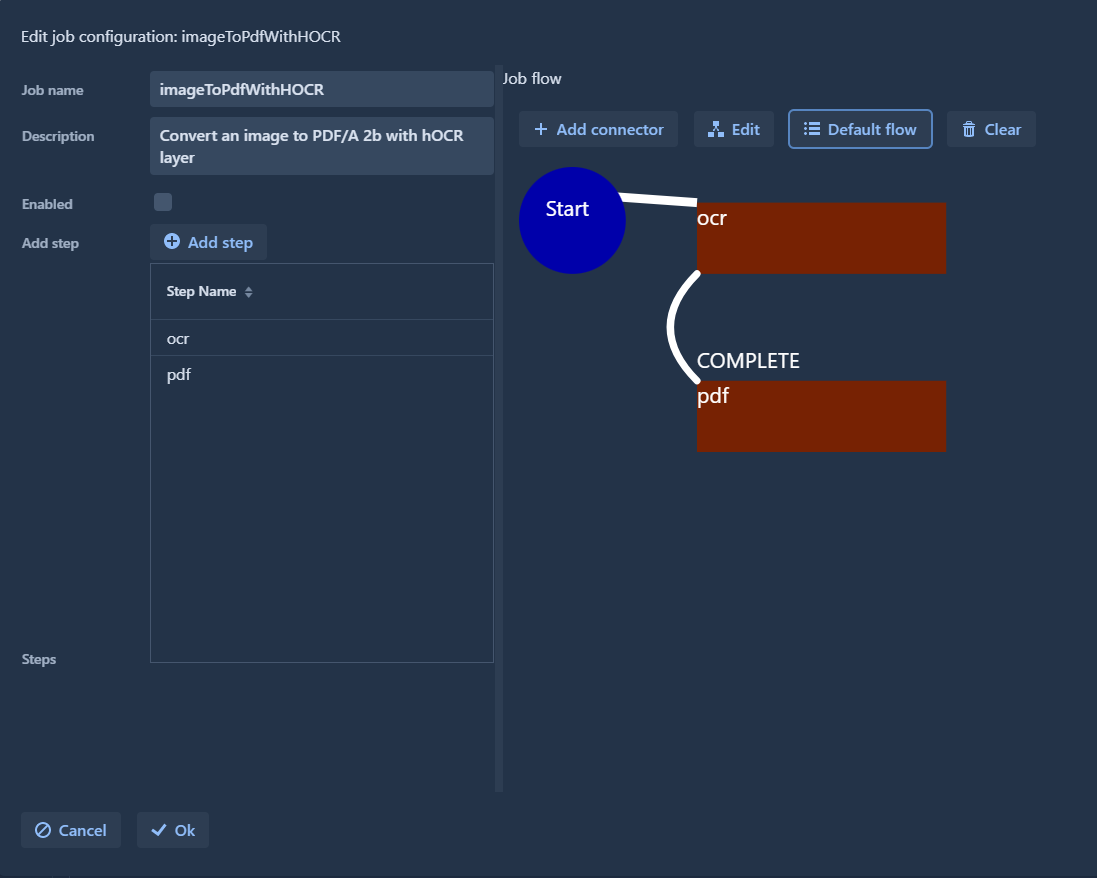
The example workflow "imageToPdfWithHocr" looks like this:

Steps can have additional configuration parameters - this is an example from the OCR-step in the UI:
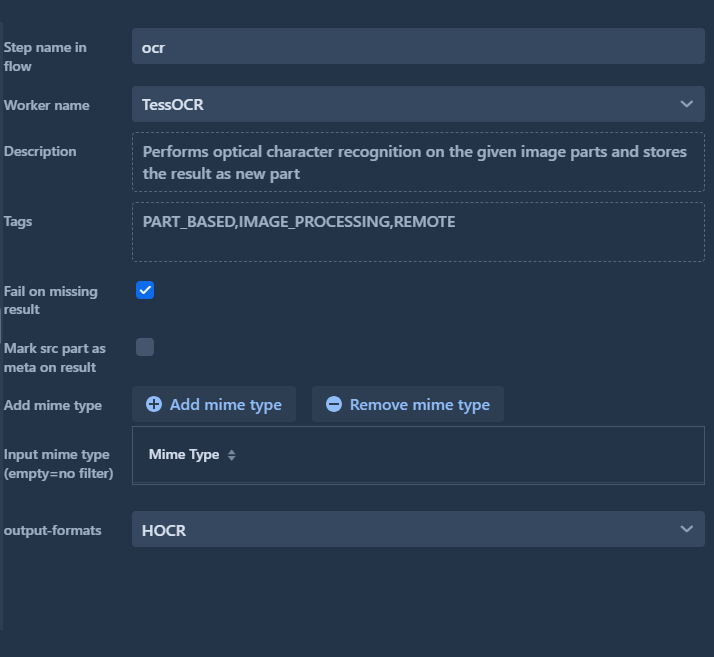
The default configuration parameters for any step are explained in more detail in the following chapters.
Yaml example
On startup of the flow controller, the defined JobTemplates from the jobTemplates.yaml will be read.
The jobtemplate.yml below has a Job with the name "imageToPdfWithHOCR". It converts an image to PDF/A 2b with hoCR layer.
The jobFlow defines the job flow graph (more details).
Example (yaml format):
---
jadice-flow.jobs:
jobTemplates:
- jobName: "imageToPdfWithHOCR"
description: "Convert an image to PDF/A 2b with hOCR layer"
properties: {}
enabled: true
stepTemplates:
- stepName: "filetypeAnalyzer"
workerDefinitionName: "FiletypeAnalyzer"
inputMimeTypes: []
expectsNewPartResult: false
markSrcAsMetaOnResult: false
parameters:
- name: "forced.types"
type: "[Ljava.lang.String;"
subTypes: []
value: ""
description: "Forces recognition of the given mime types"
- stepName: "ocr"
workerDefinitionName: "TessOCR"
inputMimeTypes: []
expectsNewPartResult: true
markSrcAsMetaOnResult: false
parameters:
- name: "output-formats"
type: "com.jadice.flow.worker.ocr.OCROutputSetting"
subTypes: []
value: "\"HOCR\""
description: "OCR output format(s)"
- stepName: "pdf"
workerDefinitionName: "CombineToPDF"
inputMimeTypes: []
expectsNewPartResult: false
markSrcAsMetaOnResult: true
parameters:
- name: "pdfaConformanceLevel"
type: "com.jadice.flow.worker.topdf.settings.Conformance"
subTypes: []
value: "\"PDFA2b\""
description: "PDF-A conformance level"
- name: "processingStepSettings"
type: "com.jadice.flow.worker.topdf.settings.ProcessingStepSettingsDTO"
subTypes: []
value: "{\"repackingAllowed\":false,\"genericProcessingAllowed\":true,\"rasterizationAllowed\"\
:true}"
description: "PDF export settings"
- name: "pdfStructureReaderSettings"
type: "com.jadice.flow.worker.topdf.settings.PDFStructureReaderSettingsDTO"
subTypes: []
value: "{\"readStrategy\":\"STRICT\"}"
description: "PDF reader settings. LENIENT-Mode enables to read some documents\
\ with structural defects"
- name: "outputMode"
type: "com.jadice.flow.worker.topdf.settings.OutputMode"
subTypes: []
value: "\"LAYERED\""
description: "PDF export output mode. Generate one stream per page or join\
\ all incoming documents together."
- name: "modcaReaderSettings"
type: "com.jadice.flow.worker.topdf.settings.ModcaReaderSettingsDTO"
subTypes: []
value: "{\"fontMode\":\"FocaRasterShape\"}"
description: "Modca reader settings"
- name: "baseReshapeSettings"
type: "com.jadice.flow.worker.topdf.settings.BaseReshapeSettingsDTO"
subTypes: []
value: "{\"pageSelection\":null,\"imageRepackingAllowed\":true}"
description: "Base reshape settings"
- name: "validationModeSettings"
type: "com.jadice.flow.worker.topdf.settings.ValidationSettingsDTO"
subTypes: []
value: "{\"performValidation\":true,\"validationMode\":\"PAGE_COUNT\",\"validationModeFailureAction\"\
:\"FAIL\"}"
description: "Validation settings"
jobFlow:
- from: ""
"on": "*"
to: "filetypeAnalyzer"
- from: "filetypeAnalyzer"
"on": "COMPLETED"
to: "ocr"
- from: "ocr"
"on": "COMPLETED"
to: "pdf"
Defining a JobTemplate
A JobTemplate should contain at least one step.
Each JobTemplate has the following default configuration:
enabled: Job templates can be disabled. Disabled templates are not available in the list of job templates for the user in the UI and requests which correspond to a disabled template will lead to an error message for the Rest-Caller.Step Name: Name of the step in the workflow / JobTemplateWorker Name: Name of the Worker for this step. The list of available workers is determined by theworkers.yamlconfiguration file. TheWorker Namemust match an existing worker configuration from the configuration file.Fail on missing Result: Many workers (e.g. ImageConversion) are expected to return a result and should use this configuration option. If a worker does not return a new data stream result, the Job would fail in such case.Mark src as meta on result: Whether to mark the source part which was sent to the worker asMETA, indicating that the part has been processed. This is an important mechanism to understand: by default, a META part will not be processed by further steps. So if a source image part has been marked as META, it will no longer be processed by following workers.Input mime type: An optional filter which can be set for the step. If one or more mime types are entered here, only parts / items which have the corresponding mime type will be sent to the worker.
Many steps have additional configuration parameters, like the OCR-output mode in the ocr worker. The possible worker configuration parameters are defined in the workers.yaml file with their descriptions and default values. In the jobtemplates.yaml, which contains the specific configured jobTemplates, the parameters are also present with their specific values for the job template.
JobTemplates can be configured via the UI which utilizes the Rest endpoints to create/modify a JobTemplate. Another option is to directly enter the template in the jobTemplates.yaml (only recommended for advanced users).
Job flow
When defining a JobTemplate, the job flow has to be defined. The UI provides a convenience method to create a simple default sequential flow of the available templates.
A sequential flow is usually sufficient for most usecases, especially if there are not many steps. However, in some cases it might be interesting to define a more complex workflow with conditions.
Simple sequential flow
When defining a sequential flow via the UI or yaml, the steps are added as Nodes to a graph. A Node has a successor, a predecessor and a condiion, in which the successor shall be used.
A special case is the first node, which does not have a value for the from-Field.
Example sequential flow:
jobFlow:
- from: ""
"on": "*"
to: "ocr"
- from: "ocr"
"on": "COMPLETE"
to: "pdf"
This example is a JobTemplate with 2 sequential steps:
ocr: Performs optical character recognition for input images (start node syntax: from="", on="*", to="ocr")pdf: Converts images to PDF
Steps usually have an exit status of COMPLETE or FAILED after they ran. Some steps might also provide a different exit status. This is generally just a String which is used to find the next node.
When defining on=COMPLETE we make sure that ocr-step was successful (or skipped).
Conditional flow
Apart from sequential flows, it is possible to define more complex flows using conditions.
As an example, we consider the following flow graph:
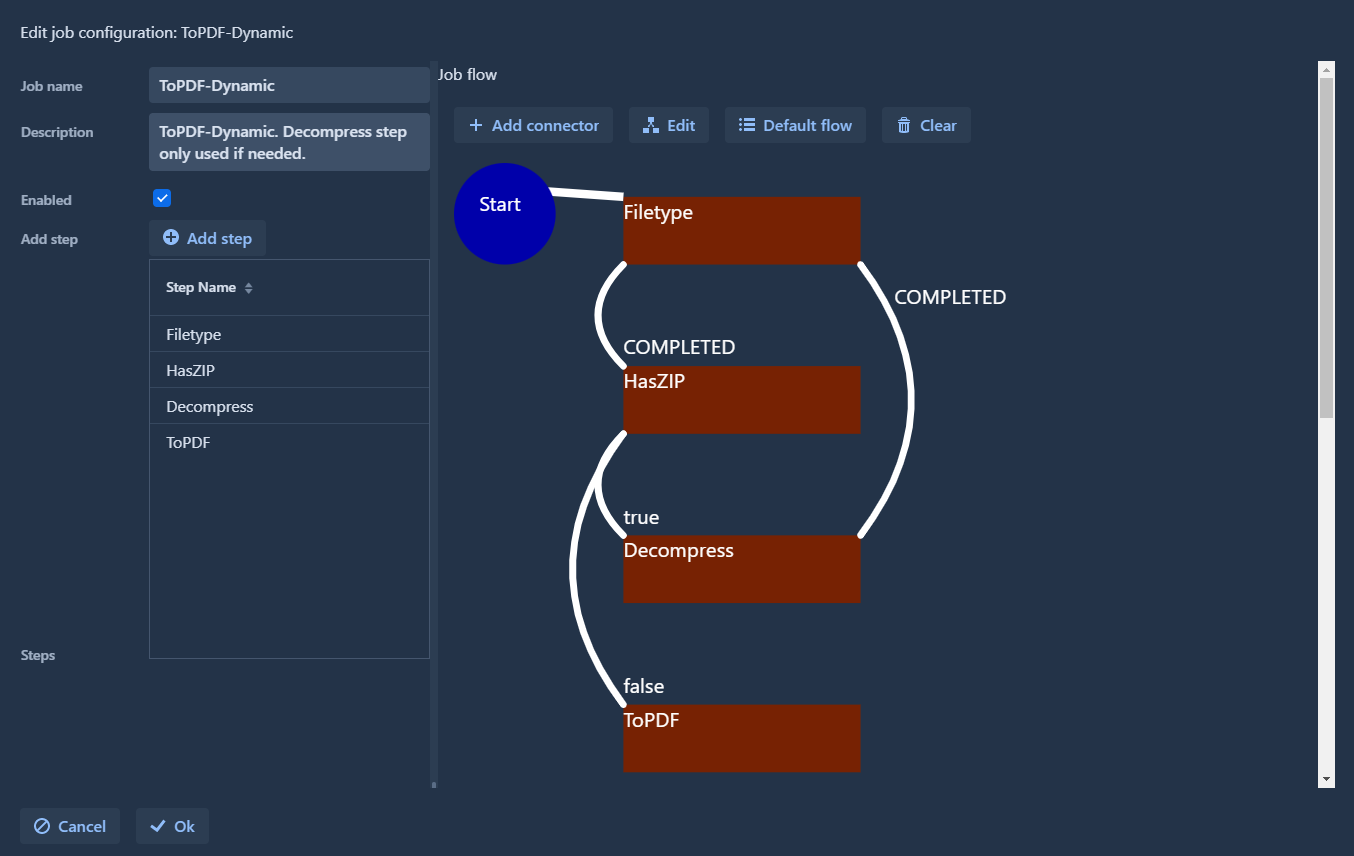
This is the corresponding yaml section:
jobFlow:
- from: ""
"on": "*"
to: "Filetype"
- from: "Filetype"
"on": "COMPLETE"
to: "HasZIP"
- from: "HasZIP"
"on": "true"
to: "Decompress"
- from: "HasZIP"
"on": "false"
to: "ToPDF"
- from: "Decompress"
"on": "COMPLETE"
to: "Filetype"
This job has the following steps:
- Start node:
Filetypeto analyze the mime type of parts HasZIPis a special step which uses theHasMimeTypeExitStatusProcessor. If theapplication/zip-formats are added to the configuration of that step, its return status will betrueorfalsedepending on whether such a mime type is present in the item. This step will not exit with COMPLETED or FAILED.- In the Node-Graph, the
Decompressstep is only called if the item really has a ZIP. After decompressing, the flow moves back to theFileTypestep, so the extracted files also run through the flow.
This example job template could be used to recursivly extract a ZIP containing further ZIPs.
Considerations regarding conditional vs sequential flow
In a conditional flow, steps might only be executed if they are needed by at least one item.
For example in a OCR job when processing PDF documents: If there are multiple items in the job, some items might need OCR, others might not. In this case the step runs (but will skip those items with text already present). Still, the step is in the step-list. Only if no item needs OCR, the step will not be executed at all.
In a sequential flow, this filtering will also take place. The step will show up in the list, but will recognize the parts which do not need OCR and only perform the call to the OCR worker if it is really needed. The step is always shown in the step list.
This leads to the following conclusions:
- When running jobs with multiple items, sequential flow should be preferred
- Conditional flows are well suited in cases where there is only one item per job
- In a migration example where a lot items have to be processed - multiple items per job and a sequential flow is recommended.
- If the controller is used as an ad-hoc service for single item requests (e.g. for user requests with one item), a dynamic conditional flow can be used.
- The products usually come with pre-defined templates, so these configurations are a more advanced use case. If in doubt, use a sequential flow and use an input filter in the step configurations to skip item/parts if needed.